




Распознавание текста на изображении с C# и Tesseract

Технология распознавания символов с изображения в редактируемый текст достаточно непростая задача. Для подобных целей используется технология OCR - Optical Character Recognition(оптическое распознавание символов). Данная технология хорошо реализована в таких фреймворках как FineReader, IronOcr для платформы .NET, Tessarect и др. Мы будем использовать последнюю библиотеку.
В статье мы опишем создание оконного приложения на C# и Windows Form в программе Visual Studio 2012. Также понадобится установить пакет Tesseract и файл для распознавания символов языка.
И так приступим.
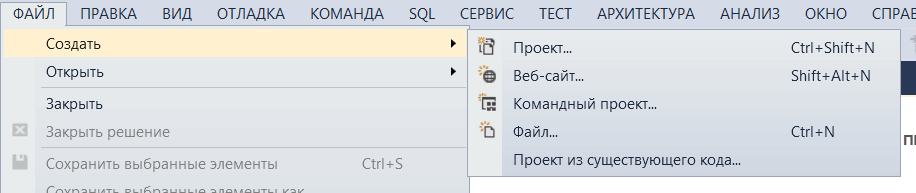
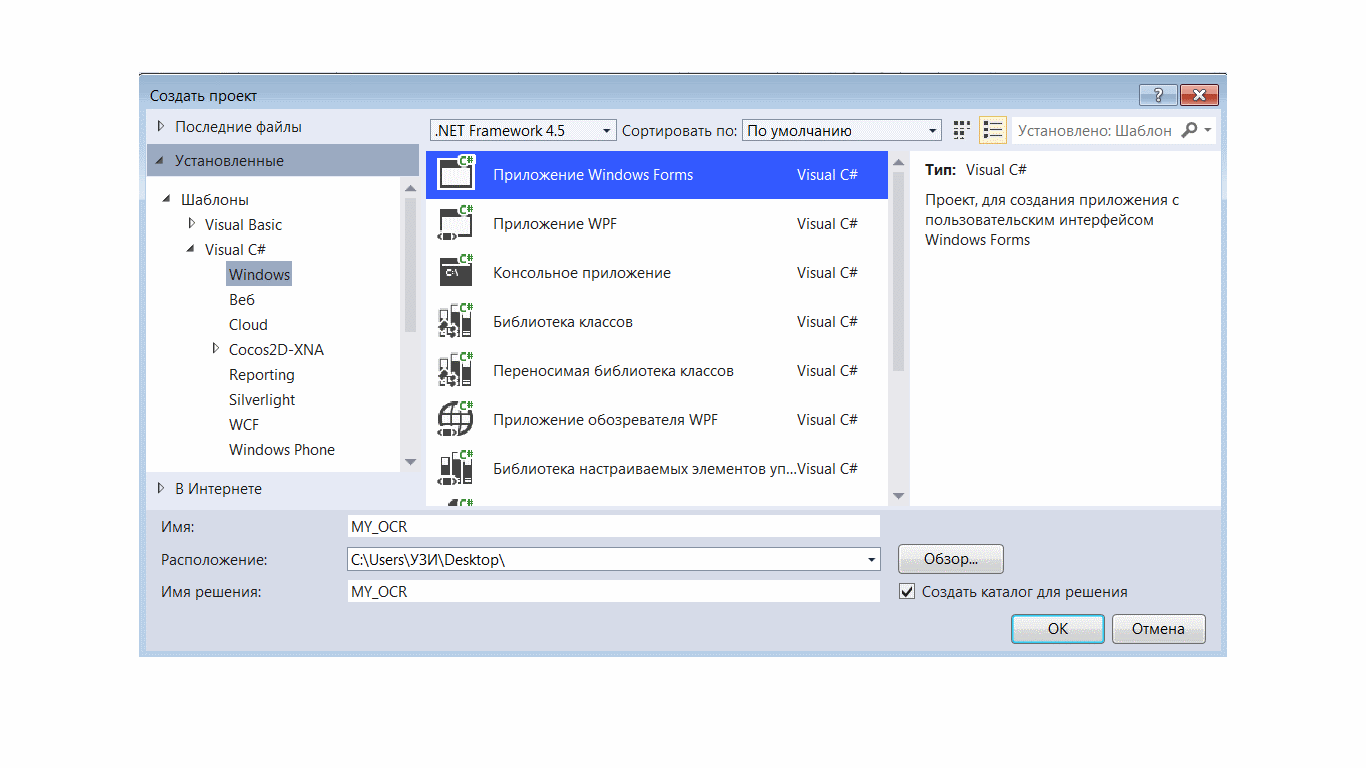
Шаг 1. Откройте программу и создайте новый проект.
Нажмите «Готово». Приложение Windows Form будет создано, как показано ниже.
Шаг 2. Установка пакета Tesseract через менеджер пакетов.
Прежде чем продолжить, нам нужно установить пакет NuGet для Tesseract.
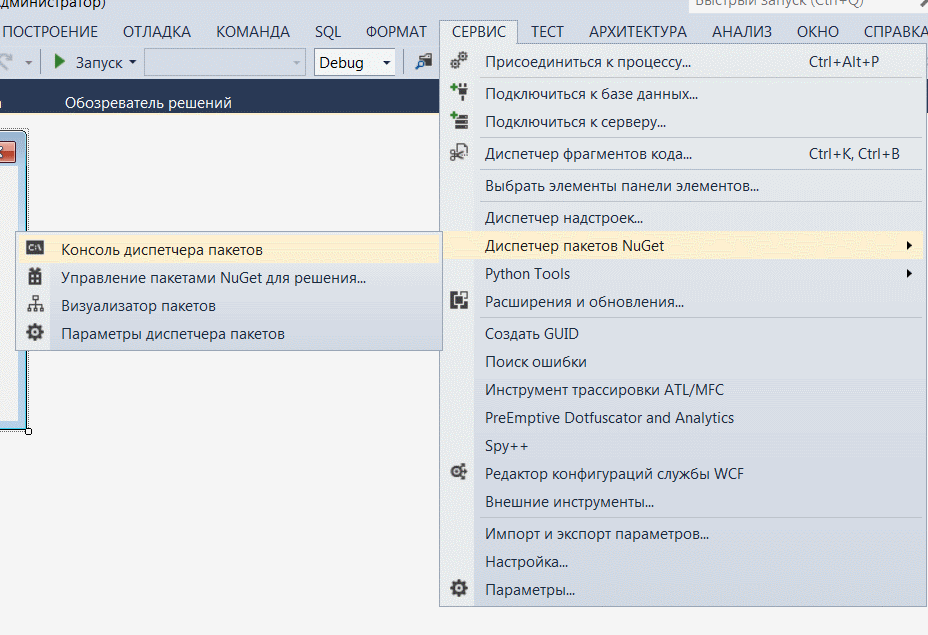
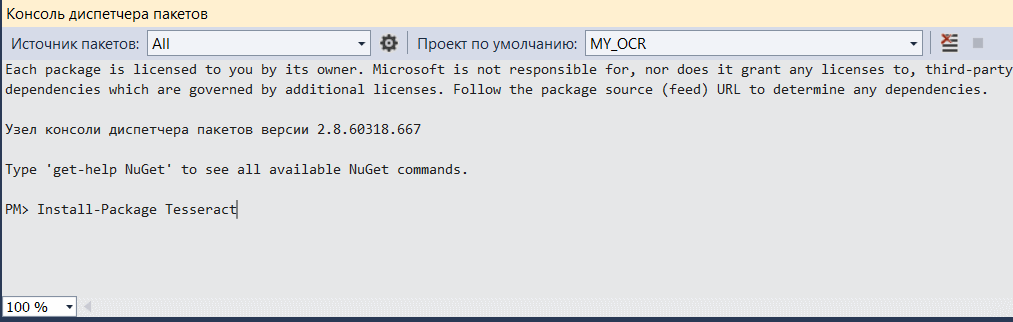
Перейдите во вкладку сервис > диспетчер пакетов NuGet > консоль диспетчера пакетов, в появившемся окне введите Install-Package Tesseract и нажмите Enter. Дождитесь окончания загрузки.
Шаг 3. Проектирование внешнего вида Windows Form
Откройте панель элементов во вкладке Вид.
Перетащите одну метку lable(для маркировки нашей программы), две кнопки button(одну для выбора изображения и другую для преобразования изображения в текст), одно текстовое поле TextBox для отображения пути к изображению, одно поле изображения для отображения изображения PictureBox, и одно поле Rich Text Box для отображения извлеченного текста.
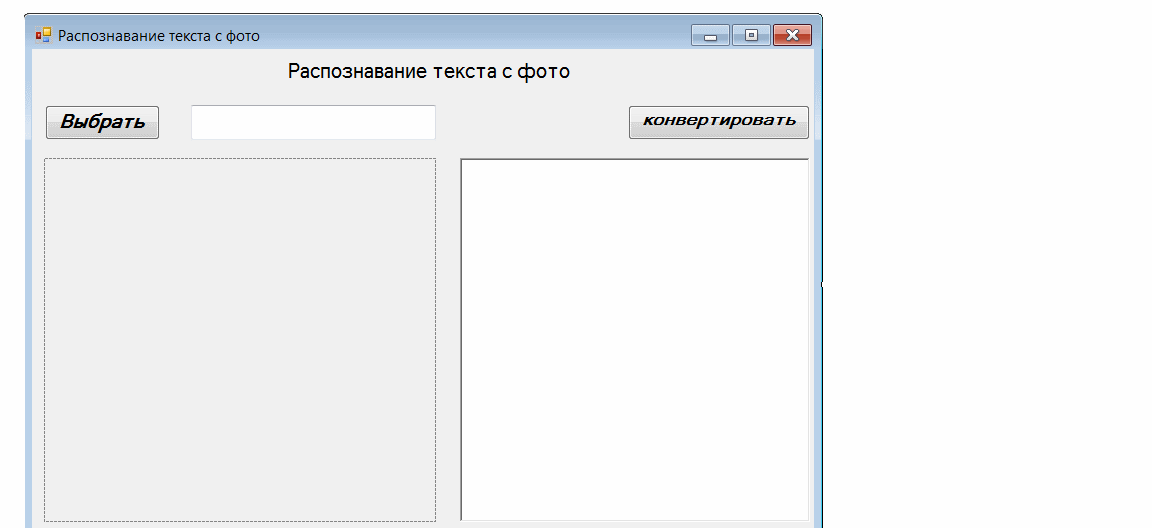
Дизайн формы по вашему выбору. Я разработал его следующим образом:
Шаг 4. Создание логики и привязка ее к кнопкам на экране. После установки пакета Nuget необходимо вручную установить языковые файлы в папку проекта. Можно сказать, что это недостаток именно этой библиотеки. Загрузите языковые файлы по следующей ссылке. Разархивируйте его и скопируйте папку tessdata в папку debug вашего проекта. Дважды щелкните мышью по кнопке на форме. Visual Studio сгенерирует следующий код:
private void button1_Click(object sender, EventArgs e)
{
}
Затем напишите следующий код внутри функции button1_Click:
private void button2_Click(object sender, EventArgs e)
{
OpenFileDialog open = new OpenFileDialog();
open.Filter = "Image Files(*.jpg; *.jpeg; *.gif; *.bmp; *.png)|*.jpg; *.jpeg; *.gif; *.bmp; *.png";
if (open.ShowDialog() == DialogResult.OK)
{
pictureBox1.Image = new Bitmap(open.FileName);
ImagePath.Text = open.FileName;
}
}
Также щелкните дважды по второй кнопке. В начало кода добавьте пространство имен: using Tesseract;.
private void button2_Click(object sender, EventArgs e)
{
var ocrengine = new TesseractEngine(@".\tessdata", "rus+eng", EngineMode.Default);
var img = Pix.LoadFromFile(ImagePath.Text);
var res = ocrengine.Process(img);
richTextBox1.Text = res.GetText();
}
Шаг 5. Запуск проекта.
Нажмите Ctrl+F5 для запуска:
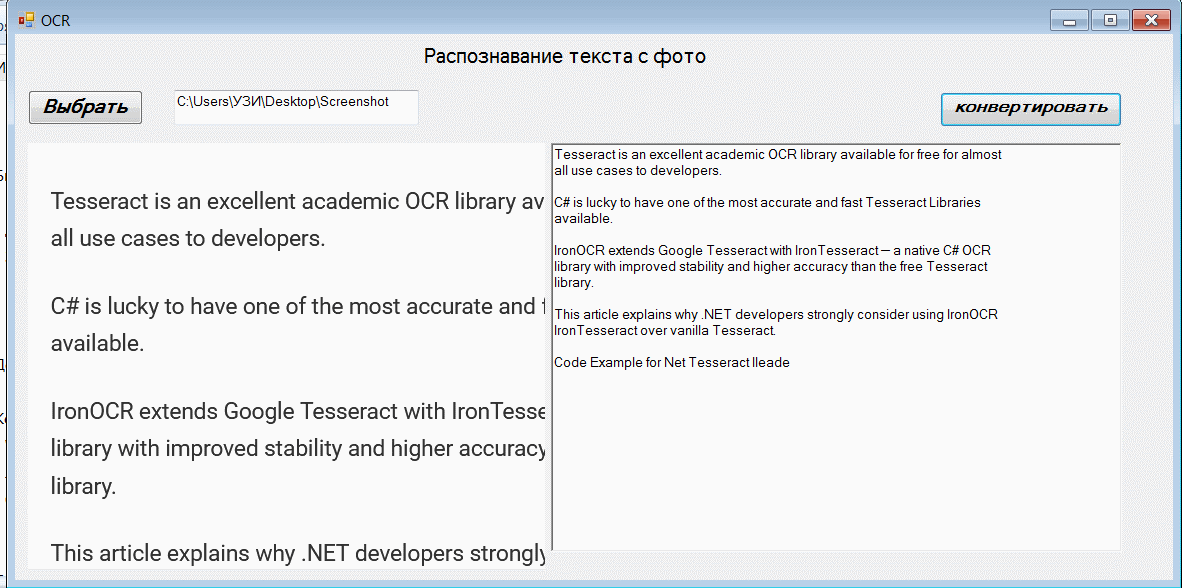
Где это может пригодиться? При сканировании или распечатке документов может понадобиться их редактируемая копия. Например, если вы сканируете бумажный документ или фотографию на принтере, принтер, скорее всего, создаст файл с цифровым изображением. Файл может быть в формате JPG/TIFF или PDF. Затем вы можете загрузить этот отсканированный электронный документ в программу OCR. Программа OCR распознает текст и преобразует документ в редактируемый текстовый файл. Таким образом, вы сможете извлекать текст из изображений с помощью C# в Windows Forms или ASP.Net для веб страницы.
-
Создано 24.03.2022 10:21:37

-
 Михаил Русаков
Михаил Русаков

Комментарии (0):
Для добавления комментариев надо войти в систему.
Если Вы ещё не зарегистрированы на сайте, то сначала зарегистрируйтесь.